Digitizing
Speech Recordings for Archival Purposes
Working Paper on Digitizing Audio
for the Nation Gallery of the Spoken Word and
the African Online Digital Library
MATRIX:
The Center for Humane Arts, Letters and Social Sciences Online
at
Michigan State University
Goals
The
bulk of the "National Gallery of the Spoken Word" (NGSW) digitization process involves digital processing
of speech signals. All of the sound archives in question exist in the
analog format. They are usually stored on a variety media, including
wax cylinders, LPs, reel-to-reel tapes, and audio cassettes. The content
of those archives is, by and large, speech. The primary purpose of digitization
is preservation. However, the digital format of audio recordings lends
itself to a variety processes ranging from delivery over the Internet
to speech recognition-based searching. The digitization process, obviously,
is not a simple one and it poses a number of challenges that the archivist
needs to address. Some of those challenges are due to the variety of
original media, media quality, and recording quality. Other concerns
include the choice of the digital file format, its characteristics,
the storage medium, as well as the choice of appropriate hardware, software,
and digitization procedures. Finally, due to the large volume of the
collections to be digitized, work flow and quality control issues have
to be carefully addressed. This paper outlines some of the key concepts
in speech digitization and a working model for digitizing speech for
archival purposes.
Choosing
appropriate digitization standards
For
the purposes of the analog-to-digital conversion of most of VVL audio
recordings, we have chosen to use a 44,100 Hz sampling rate and a 16-bit
resolution. The details of this decision, as well as the process itself,
are delineated below.
The
choice of appropriate digitization standards seems to be influenced
by two distinct factors - the technological and the archival. Each of
these factors poses a different set of questions and challenges to the
project. When deciding on particular specifications of sampling rate,
quantization, hardware, etc. our primary technological goal is to provide
a digital copy that closely matches the analog original. In the technical
sense, we need to establish a process that, minimally, reconstructs
the entire frequency response of the original while adding as little
of the so-called "digital noise" as possible. To achieve this goal,
it seems to be sufficient to use the 44,100 Hz sampling rate and a 16-bit
resolution. The former ascertains that we capture the entire audible
frequency range of the original (see Nyquist theorem below), while the
latter, gives us a fairly good, 96 db SNR (signal to noise ratio). From
the archival standpoint, it is our desire to preserve as much information
(both speech and non-speech) of the original as possible. The technical
specifications mentioned above promise to fulfill this goal.
In the
ideal world, the discussion on choosing appropriate standards could
end right here. However, there are a few other issues involved. Current
technology makes it possible to use higher sampling rates and resolution.
One could fairly easily sample at 96,000 Hz and a 24-bit resolution.
This would result in a much increased frequency response of the digital
waveform � from 0 to 48,000 Hz, and a dramatically improved SNR of
144 dB. At first glance, this technology appears to provide a very
simple solution. After all, it is our goal to preserve as much information
as possible, and using such high specifications does exactly that.
The digital audio file captured at 96,000 contains over twice as much
information as the one sampled at 44,000 Hz. The question, however,
is whether the extra information included in the 96,000 Hz file is
worth preserving.
NGSW
recordings can be easily characterized as limited bandwidth. First
of all, they are all analog speech recordings. Speech, as such, is
a rather narrow-bandwidth medium. In fact, the highest frequency speech
sounds, voiceless fricatives, such as /th/ and /f/ have an upper frequency
of about 5,000 � 6,000 Hz, depending on the age and gender of the
speaker. Thus, any information in the channel that is above the 6,000
Hz is, without a doubt, non-speech information. Of course, from the
archival standpoint, we may want to preserve this information, too.
That could be any "environmental", ambient sound present in the recording.
Second, most NGSW recordings have been mastered on a limited-bandwidth
analog equipment that was not capable of capturing any of the high
frequency information in the first place. The Nyquist frequency in
such recordings varies, but it hardly ever goes beyond the audible
range of 20-20,000 Hz.
In light
of these facts, the higher specifications help us capture nothing
but silence. The spectrogram below illustrates a phrase: /yacIyesteshmI/
converted to digital at 96,000 Hz. As we can see, acoustic content
of this file occupies only the lower 1/3 of the spectrum. Anything
above that is silence.
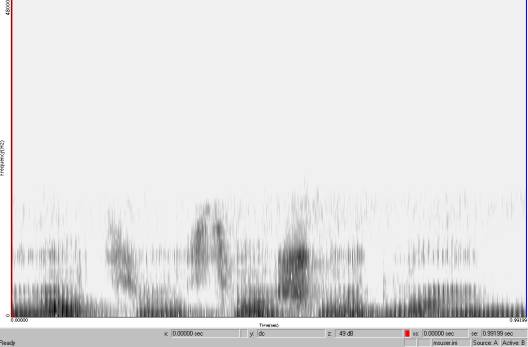
The
question of whether we should adopt the higher specifications, however,
still remains to be answered. Beside that facts mentioned above, it
has been suggested in psycho-acoustic literature that higher sampling
rates do have a clear perceptual effect. Most of the experiments done
so far have focused on music, especially recordings originally captured
at 96,000 Hz. It still remains to be seen whether this effect is present
in speech recordings, especially those converted from analog media.
One last remaining issue is the effect of anti-aliasing filters used
in a process clocked at 96,000 Hz. Arguably, one could apply a filter
with a slope much less steep than in the process clocked at 44,100 Hz.
NGSW sound engineers are currently in the process of researching the
perceptual effects of higher sample rates and more gradual anti-aliasing
filters. The decision of whether to use 96,000.24-bit specifications
largely depends on the results of those tests. In making the decisions,
NGSW will also consider the issues of data storage and migration, as
well as available processing power. It must be noted that higher digitization
standards require considerably more storage space and processing power.
Basic
Concepts
Digitization
Digitization
is a process of converting an analog, or continuous, waveform to digital
form by an analog to digital converter
(ADC). The sound pressure
waveform is a continuously varying signal. It changes from instant to
instant, and as it changes between two values, it goes through all values
in between. Using an ADC, the signal is sampled at a set of equally
spaced times. The sample value is a number equal to the signal amplitude
at the sampling instant. Computers always represent numbers internally
in the binary number system, where each binary position can be one of
the two binary digits, 0 or 1. Each binary digit is called a bit,
and a collection of eight bits is called a byte.
The astonishing
thing about the ADC process is that, if done properly, every detail
of the original signal can be captured. The original continuous waveform
can be reconstructed exactly and, more importantly, powerful digital
signal processing can be applied to the digital representation of
the signal. Such a representation can then serve a variety of purposes,
such as streaming, watermarking, speech recognition, etc. A vast number
of effects, such as noise reduction, bass emphasis, normalization,
compression, etc. can be achieved by applying a mathematical transformation
called "a digital filter." After processing , the resulting
continuous signal can be reconstructed without any degradation. The
process of converting from digital back to a continuous signal is
called digital to analog conversion,
or DAC.
When
any signal is transmitted over a communications medium, it is inevitably
distorted to some degree. The received signal, therefore, differs
to some extent from the originally transmitted signal. For an analog
signal, even small amounts of distortion lead to noise that is often
impossible to eliminate. Examples of noise include "hiss",
"static", and the poor quality (limited bandwidth) of signals
transmitted over telephone circuits. For digital signals, the same
signal distortion factors are present. However, since the signal at
any instant of the represents a number, rather than an analog signal
level, it is necessary only to unambiguously recognize the number
that was transmitted. This choice is substantially eased by the fact
that digital signals are binary. As long as noise is small enough
so that the choice between these two outcomes is not confused, the
received signal will represent the same numerical value as the transmitted
signal. In fact, additional coding techniques, such as parity check,
are used to detect and correct errors that might occur in the process.
The result is unparalleled quality and robustness of digital signals.
The sampling
theorem
It
is not obvious that an exact reconstruction of an analog signal should
be possible, since a complete continuous signal is replaced by a finite
number of samples taken at equal time intervals. The problem is to have
complete information between the samples. The answer lies in the mathematical
result called the Sampling Theorem.
In short, the sampling theorem states that if a band-limited signal
is sampled at a rate greater than twice the highest frequency in the
signal (the so-called Nyquist frequency), no information is lost
and the original signal can be exactly reconstructed from the samples.
Acoustic signals that humans can hear lie in a limited range of about
20 to 20,000 Hz. Thus, intuitively, in order to exactly reconstruct
the original analog signal one should use the sample rate of at least
40,000 Hz. This is, indeed, true. It is recommended to use the standard,
CD quality, sample rate of 44.1 KHz for all of spoken word digitization
projects. It is important to note that sampling at a rate lower than
twice the Nyquist frequency results in a phenomenon called aliasing,
whereby the resulting digital signal lacks a significant number of bits
of information and it may be severely distorted by the aliased components,
making it audible as noise. Finally, even though the speech signal usually
does not contain any information above 7 kHz, and, theoretically, the
sample rate of 16 KHz should be sufficient to capture all details of
the signal, it is nevertheless recommended to use the sample rate of
44.1 kHz for all of AD conversion for archival purposes.
Quantization
For
the sampling theorem to apply exactly, each sampled amplitude value
must exactly equal the true signal amplitude at the sampling instant.
Real ADCs do not achieve this level of perfection. Normally, a fixed
number of bits (binary digits) is used to represent a sample value.
Therefore, the infinite set of values possible in the analog signal
is not available for the samples. In fact, if there are R
bits in each sample, exactly 2R sample values are possible.
For high-fidelity applications, such as archival copies of analog recordings,
16 bits per sample (65, 536 levels), or a so-called 16
bit resolution, should be used. The difference between the analog
signal and the closest sample value is known as quantization
error. Since it can be regarded as noise added to an otherwise perfect
sample value, it is also often called quantization
noise. The effect of quantization
noise is to limit the precision with which a real sampled signal can
represent the original analog signal. This inherent limitation of the
ADC process is often expressed as a Signal-to-Noise
ratio (SNR), the ratio of the average power in the analog signal
to the average power in the quantization noise. In terms of the dB scale,
the quantization SNR for uniformly spaced sample levels increases by
about six dB for each bit used in the sample. For ADCs using R bits
per sample and uniformly spaced quantization levels, SNR = 6R - 5 (approximately).
Thus, for 16-bit encoding about 91 dB is possible. It is 20 to 30 dB
better than the 60 dB to 70 dB that can be achieved in analog audio
cassette players using special noise reduction techniques.
The WAV
file format
The
WAV file format is recommended for storing digital versions of speech
recordings. WAV files are uncompressed, thus preserving all bits of
information recorder in the AD process. It is also widely used and easy
to process and convert to a variety of streaming formats.
The
WAV file format is a variant of the RIFF format for data interchange
between programs. This format was designed so that data in a file is
broken up into self-described, independent "chunks". Each
chunk has a prefix which describes the data in that chunk. The prefix
is a four-character chunk ID which defines the type of data in the chunk,
followed by a 4-byte integer which is the size of the rest of the chunk
in bytes. The size does not include the 8 bytes in the prefix. The chunks
can be nested. In fact, a RIFF file contains a single chunk of type
"RIFF", with other chunks nested inside it. Therefore, the
first four bytes of a WAV file are "RIFF", and the four bytes
after that contain the size of the whole file minus 8 bytes. After the
RIFF header is the WAV data, consisting of the string "WAVE"
and two important chunks: the format header and the audio data itself.
There may also be other chunks in a WAV file that contain text comments,
copyrights, etc., but they are not needed to play the recorded sound.
The header and the audio data can be easily separated to facilitate
migration to any other format, if necessary.
Hardware
A/D converter
We
recommend using a professional-level, hardware platform, preferably
integrated with the software, that includes reliable signal acquisition,
analysis, and playback, such as Kay Elemetrics' Computerized Speech
Lab (model 4300B). Such hardware should include 16-bit input/output,
auto calibration, sophisticated signal conditioning and anti-aliasing
filters to take full advantage of the 16-bit signal representation.
Additionally, the hardware should be able to offer a wide assortment
of frequency ranges, XLR (balanced) inputs, DAT pass-through, and powerful
digital signal processing circuitry for fast signal analysis. Unlike
systems built around generic plug-in multimedia sound cards (which were
designed primarily for game sound output, not input), such hardware
usually offers input signal-to-noise performance typically 20-30dB superior
to generic plug-in sound cards. There are a number of superior quality
A/D converters available on the market. It is important, however, that
the A/D converter meet the above specifications.
Hardware-based
ADC usually offers the following features:
-
Superior
S/N specifications due to isolation of analog input/output from
computer
-
Calibrated
input and sensitivity for measurement of absolute level (SPL)
-
High
gain preamplifier to accommodate low-level input signal levels
-
2-
or 4-channel input Digital (e.g., DAT) input/output
-
XLR
(balanced) microphone input for protection from noise
-
Online
feedback and adjustment of input level
-
User-selected
AC/DC coupling for all channels
-
Wide
selection of frequency ranges
-
Manual
and computer control of input and output level
-
Auto-calibration
of hardware Real-time indicator of signal overloading
The
external module also performs the initial signal conditioning and A/D
conversion. The external module isolates the low-level (e.g., microphone)
analog input signals from common sources of noise in PC-based sampled
data systems: the switching noise of digital signals, power grounding,
and unshielded power supplies. "It seems like there is so much
noise and interference going on inside a computer that it�s necessary
either to use a digital I/O or have some sort of external breakout box
with A/D converters instead of the �traditional sound� card." (Ken
Lee, New Media, April 14, 1997, pp. 33-44.)
PCI Sound
Card
The
analog signal is converted to digital by the external module. Then
it is captured by an internal PCI sound board. It is important
to avoid using standard multimedia sound cards. It is recommended
to use a professional-level sound card that meets the following specifications:
-
PCI
Interface
-
8
to 24 bit resolution
-
variable
sample rates, including 11.025kHz and 44.1kHz
-
Analog
two channel in/out via 1/4" TRS connectors
-
S/PDIF
digital in/out via gold-tipped RCA connectors
-
+4/-10dB
balanced/unbalanced operation
-
4
channel operation using both analog and digital ins and outs simultaneously
-
Analog
Input Dithering
Computer
- A
top-of-the-line PC or Mac that meets the following specifications:
- 500MHz
or higher processor
- 256
MB of RAM
- High-capacity,
fast HDD (preferably 2 Ultra 160 SCSII drives with a RAID controller
card)
- Fast
CD Writer
- Fast
DVD Drive
- IEEE
1394 card for digital in/out (optional)
Software
- A
sophisticated sound editor is recommended. It should meet the following
specifications:
- Multiple
Document Interface for editing multiple files in one session
- Unlimited
file size editing
- Real-time
graphs (amplitude, spectrum, bar, and spectrogram) (optional)
- Real-time
fast forward and rewind playback
- Numerous
effects (distortion, Doppler, echo, filter, mechanize, offset, pan,
volume shaping, invert, resample, transpose, noise reduction, time
warp, pitch, and more)
- Supports
many file formats (WAV, AU, IFF, VOC, SND, MAT, AIFF, MP3, OGG, and
raw data) and can convert to/from these formats
- Drag-and-drop
cue points
- Direct
sample editing with the mouse
Digitization
process overview

The digitization
process, is a rather straightforward one. With a little bit of training
and correct preset parameters, it could be done by anyone with basic
computing skills.
Summary
of A/D conversion settings:
- Sample
rate: 44.1 kHz
- Resolution:
16 bit
- A/D
converter settings: use plain signal with no correction. Use normalization
if necessary.
- Input
level: adjust and monitor levels to avoid signal overload. Digitization
is very prone to clipping on overload. The process of setting levels
is different for digital and analog.
- Save
as: *.wav